Separation of Storage and Compute, and Compute-Compute Separation in Databases

This blog post is intended to be an extremely simple and brief introduction to two concepts which I admittedly took longer than I would have wanted to understand. The two concepts are separation of storage and compute, and compute isolation for database systems. Hopefully, this blog post is useful to newcomers who want to get some pointers into what these are, and where else to go to for more information on them.
Separation of Storage and Compute
"Separating compute and storage" involves designing databases systems such that all persistent data is stored on remote, network attached storage. In this architecture, local storage is only used for transient data, which can always be rebuilt (if necessary) from the data on persistent storage.
This quote is from a great blog post on "Separation of Storage and Compute", which was written by Adam Storm in in early 2019. I highly recommend reading it, especially if you’re not familiar with this concept in the database ecosystem. Interestingly, the blog post ends with:
I’m of the opinion that in the coming years, it will be commonplace for all new database systems to embrace the separation of compute and storage, and the migration of existing systems to this paradigm will accelerate.
It’s been roughly 5 years since this blog post was written in 2019. Has this prediction held up? Let’s see…
- SingleStore announced "Bottomless Storage" in 2020 and it was officially launched in 2021.
- "The Future is Bottomless” and “Your Phone Already has Bottomless” are great blog posts on the matter.
- Neon.tech (Serverless Postgres) launched with “bottomless” storage in mid-2022.
- "SELECT ’Hello, World’" is a great introductory blog post to Neon’s architecture, but their docs are also a good resource.
- In mid-2022, Google announced AlloyDB, which disaggregates storage and compute as well.
- If you want to learn more, "AlloyDB for PostgreSQL under the hood: Intelligent, database-aware storage" is a good blog post on their storage layer.
- Databricks SQL was made generally available in late 2021, and it can be considered as a data warehouse with separation of storage of compute. From what I understand, it is built using Spark SQL and Delta Lake, which had been in development for many years before this.
There are more examples of course, but it’s clear that Adam Storm was right — separation of storage and compute has become prevalent in new and existing database systems.
Why did this happen? So what?
If you want to understand why separation of storage and compute took off, I again recommend Adam Storm's blog post. The three main reasons quoted in the post are Scalability, Availability and Cost (pay for what you use!). So, as more databases become cloud-native, and as new products are built in the cloud world from scratch, separation of storage and compute will only become more common.
For developers using databases to build applications, this means a lot more flexibility at a lower cost. But it might also mean some vendor lock-in, and lower flexibility to move workloads to on premise hardware. Some vendors like AlloyDB and SingleStoreDB have self-managed offerings, but this is not true for most cloud-native databases.
Compute-Compute Separation (or Read Replicas)
Another important aspect of building databases that can handle data-intensive applications is compute-compute separation, or compute isolation. This is more commonly referred to as "Read Replicas" in the database world. One important aspect to keep in mind is that "Read Replicas" can be used to achieve a couple of different things:
- Scalability/Performance
- Fault Tolerance/High Availability
- Overall Flexibility
The scalability and performance gains come from using read replicas to scale reads during busy times, or to nullify the impact of backups. Another common use case is to isolate analytical workloads (reporting, etc.) from the main operational workload. This helps users avoid ETL which increases data infrastructure complexity tremendously.
For fault tolerance/high availability, read replicas must be deployed in different AZs (Availiability Zones) or even different regions (both synchronous or asynchronous replication can be used here, to achieve varying levels of performance tradeoffs).
The fact that so many databases now have separation of storage and compute only makes it more obvious that they should also have read replicas. In theory, if you’re already separating storage and compute, having isolated compute pools should be "straightforward". Of course, that’s only true in principle (implementation of these things is really tricky).
Some of the databases that offer separation of storage and compute do it through cloud blob storage (S3 and the likes). Jack Vanlightly has this simple diagram on how data systems typically integrate blob storage ("Cloud Storage"):
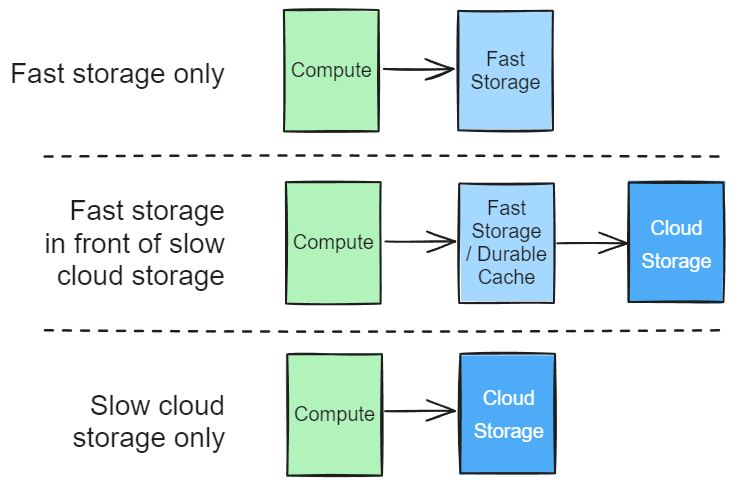
(This figure is shamelessly copied from Jack Vanlightly’s outstanding blog post titled "The Architecture Of Serverless Data Systems")
The difficulty of supporting read replicas doesn’t vary too much between these three architectures. However, if a database is leveraging blob storage for asynchronous replication of data, then the possibilities are a bit more interesting for things like cheap read replicas across AZs in the same region. However, the bulk of the work to implement read replicas properly is always roughly the same. Database providers need to build a replication system that ensures the lowest possible latency between different deployments (you can think of these as processes, or services). There are different ways to build this kind of replication, but I quite like this talk from Rodrigo Gomes about how we did it at SingleStore.
All in all, read replicas are an excellent feature that is extremely commonplace in the industry:
- Neon has "Instant Read Replicas"
- SingleStore calls them "Workspaces"
- Of course, the more classical database systems have them as well. The AWS RDS/Aurora docs on these are very good
And how does sharding play into this?
Data-based replicas, often called shards or partitions, are used to scale a workload horizontally with more query parallelism. These can also be somewhat useful to implement high availability, but their main purpose is higher scalability. They are completely decoupled from read replicas, and a DBMS vendor might support both, or just one of the two, or neither.
That's all for this post. There a lot more that I could cover here, but I find that these concepts are best absorbed incrementally over time. I want to thank the many people from SingleStore who, over the years, have helped me learn all these things.
Feel free to reach out on Twitter!