The Old York Times — Shift APPens 2016 Hackathon Project (Post Mortem)

This past weekend two friends (Pedro Paredes and “Michel” Duarte) and I took part in a hackathon held in our hometown — Coimbra, Portugal. It’s called “Shift APPens” and participants are allowed to build both apps and games in only 48 hours. I think our project was quite special, hence I decided to write about it.

After seemingly endless brainstorming, we decided to build an application that would let users browse through news for a given location and range in time. Sounds complicated? I’ll give you a couple of examples to make it easier to understand. One use case could be looking up what went on in South America during the 18th century, while another one might be to catch up on what happened last month if you were away without Internet.
So, the first challenge at hands was to get as much data (news) as possible. Thus, we decided to scrape Wikipedia and OnThisDay for this task. The former allows us to search for any year in history and the latter is a platform for browsing all kinds of events from the past. We set out to build a crawler for Wikipedia and OnThisDay but then we faced another, tougher challenge.
We ended up getting around 100K different news to work with, but each one is only a small 7–30 words headline, without any location or category tag. In order to get the location, “Michel” created a small script using NLTK that attempts to get the location for a given news headline. It looks for nouns in the sentence and uses them to determine the location of the news (for instance, “Berlin” suggests that it went on in Germany, and other tricks like this one).
To retrieve the category for each headline, we opted for a Machine Learning approach. Pedro manually annotated the category for over one thousand headlines and then we used a Naive Bayes classifier with words as the different features (some weighing more than others though) to classify the remaining hundred thousand news.
After all of this, we had to grab images for the news and Pedro wrote a script that ran for about 24 hours which queried Bing and grabbed the first result. Waiting for this to finish was truly painful, as any upset with the Internet would basically break it. Fortunately (perhaps miraculously?), it all worked out and despite not delivering the best results, it worked pretty well for what we needed.
Moreover, we had to somehow rank the news by relevancy. We started out by searching the headline on the Internet and then using the number of results it got, but this worked very poorly so we also built a manual upvote/downvote system that we used throughout development to improve the accuracy of the service.
Now, at last, there are a a few special things about the interface that I’d like to point out, because it was mostly my responsibility in the project. Given the time we had, we are proud of this UI because despite being simple, it works fairly well and also looks cool.
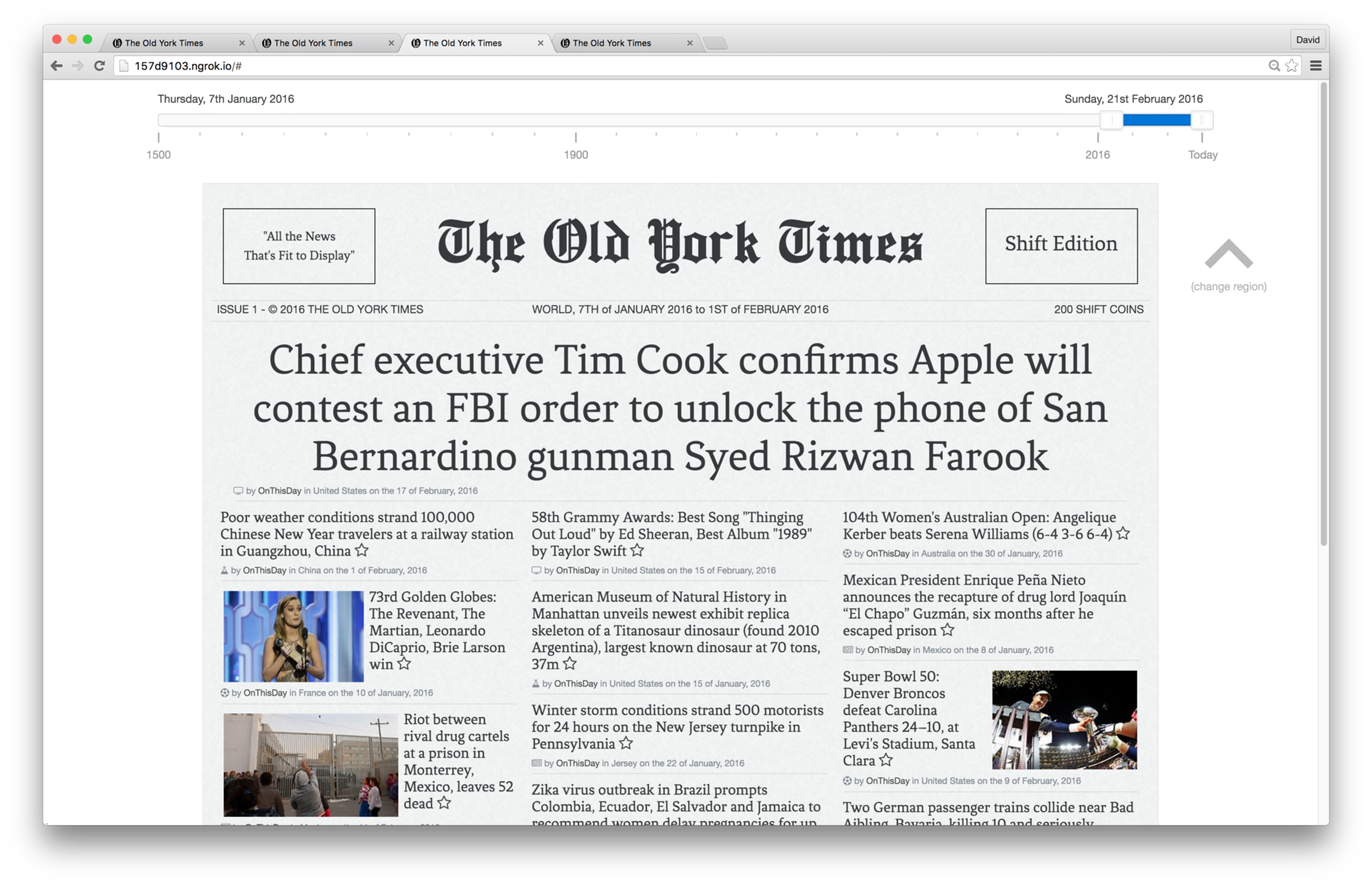
We thought it’d be cool if we presented the results in the form of a newspaper cover, to give the users the feeling of going back in time while reading the news. In fact, we even implemented three different newspaper layouts to match the era of their time range. I think this worked out pretty well, as the people who tried it out really liked it.
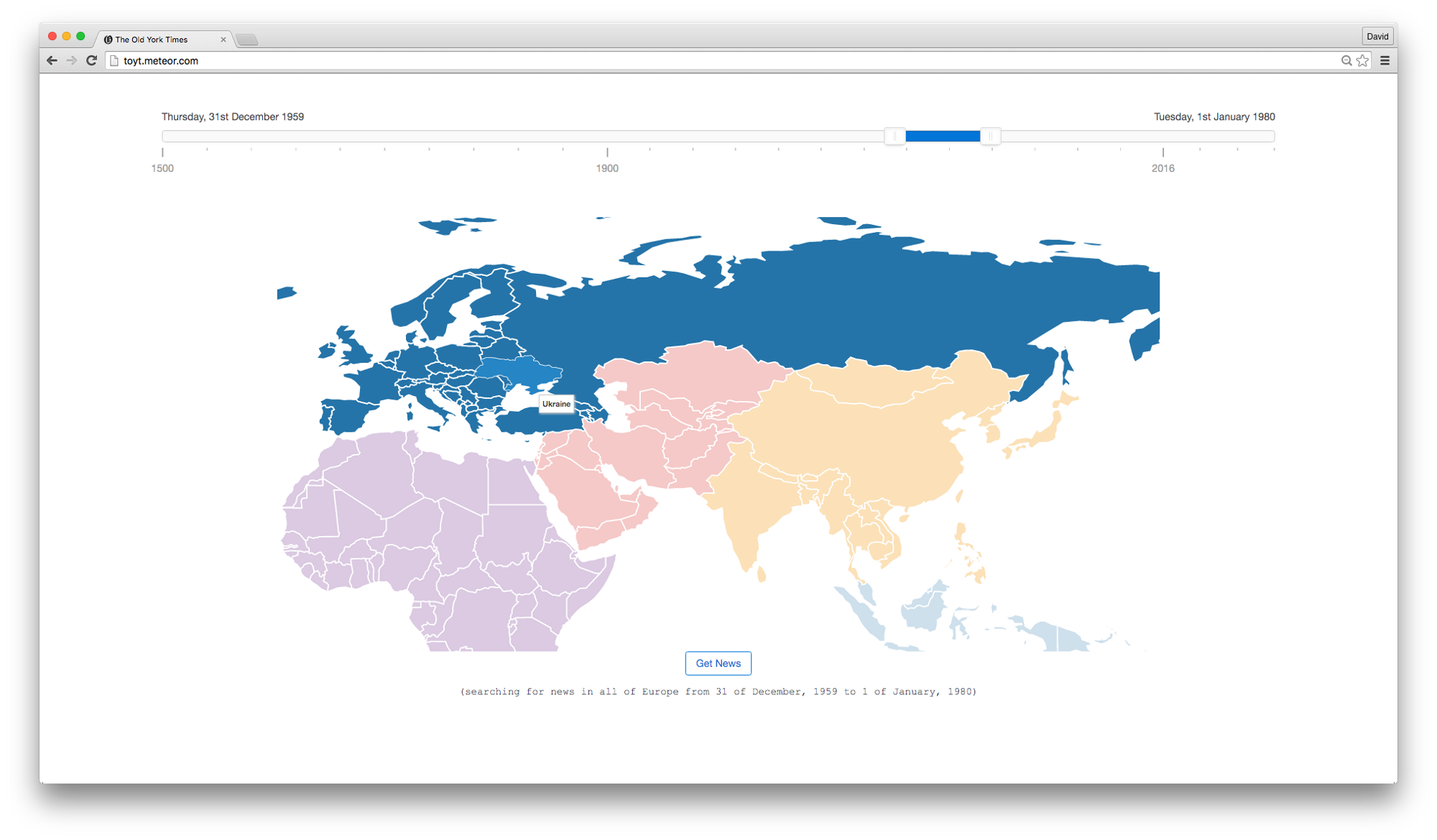
Secondly, we also put a lot of focus on the interface for selecting the query to search for, and I implemented a very fancy map with zoom animations and country/continent selection based on DataMaps. At the top, you can find a slider which lets you choose the time range for the search, based on noUiSlider. The interesting feature about the slider is that the scale is non-linear, meaning that it is easier to select more accurate intervals for 2016 or the 20th century.
All in all, the event was pretty great, with lots of food, random activities, amazing participants and very helpful staff. Bonus points because we ended up winning the hackathon itself! (also, you can maybe try our app here, but we can’t guarantee it’ll be up)
