The Dynamics of Flaky Tests and Which To Remove

I recently wrote a blog post titled “A Simple System for Measuring Flaky Tests in a Large CI/CD Pipeline”. We have implemented this system at work and it has been working wonderfully for us. After implementing this, we are now able to track the percentage of tests that fail and the percentage of full CI/CD pipelines that fail.
Our “flaky test score”, i.e., the number of tests that fail due to flakiness is 0.01% to 0.03%. This seems pretty low, but since each pipeline runs over 4000 tests, it’s very easy for a pipeline to still fail (since only one test needs to fail for the entire pipeline to fail). Currently, we’re hovering between 30% and 60% of pipelines failing.
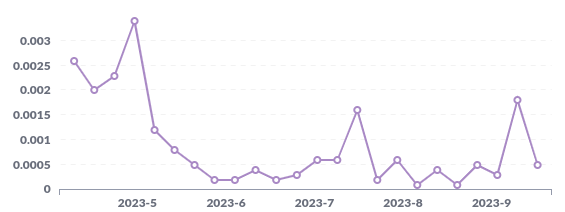
This chart above shows our week-to-week “Flaky Test Score” (as a ratio, so 0.0001 corresponds to 0.01% of all tests failing).
Now, the following chart, which admittedly looks a little scary, shows the percentage of full pipelines that fail week-to-week.
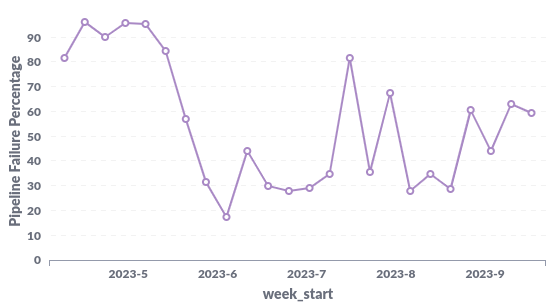
We only started properly tracking this data around 4 months ago, so we still have a long way to go to improve these metrics.
The most important thing we have to do is remove flaky tests from the codebase, fix them (i.e., make them non-flaky), and re-add them. This sounds simple enough, but in reality, this is very hard to do. Why is that?
- Some of these tests are really important and we can’t just outright remove them as that would be too risky.
- A lot of the flaky tests have been around for many years, and they don’t have a clear owner (some of the authors of these tests have changed teams or left the company). So, it’s sometimes hard to find someone to work on a given test.
- Fixing the flakiness is often extremely hard and requires multiple days if not more than a week of investigation.
To address these issues, we’ve setup a Flaky Test Rotation. The goal of this rotation is to have a dedicated engineer that rotates every 2 weeks who has the following responsibilities:
- Triage flaky tests, remove them from the codebase, and file tickets (I’ll get back to this later)
- Fix flaky tests that don’t have a clear owner.
- Do other improvements to our CI/CD pipeline that improve its reliability, performance or its observability.
One thing that’s been very hard for us to work around has been how to identify which flaky tests we can actually remove from the codebase. How can we identify the tests that should be removed? This is a bit subjective, but here’s a rough guideline:
- If the test is “fresh”, i.e., it’s relatively new, and it has a clear owner — we should almost always remove it. A task should be filed to the owner to fix it.
- If the test doesn’t have a clear owner, it becomes a bit more complicated. Here, we have to check if the test is critical or not. We try to use our “Flaky Test Rotation” to fix these tests.
- If the feature being tested is in “Public Preview” or “Private Preview”, we should also remove it as well. Also, if it’s a feature that’s only enabled for a very small number of customers, or some sort of legacy feature, the same criteria applies.
Of course, the decision always has to be made on a case by case basis. And the more structured your codebase is, the easier it will be for individual teams to own their tests and make decisions on their own. If your software is more monolithic, and there’s parts of it without clear owning teams, it becomes much more complicated to triage and distribute this type of work. We’re striving towards having owning teams for every single test in the codebase, but that is not a quick and easy process.
Finally, I’d like to note that fixing flaky tests is not just about making pipelines pass more frequently. If a test is flaky, often times, the feature that it is testing is itself flaky (i.e., the feature might not always work). This only makes it all the more important to diagnose flaky test failures.
So, all in all, dealing with flaky tests and flaky CI pipelines is not just challenging from a technical perspective, but also as it pertains to team dynamics. I hope this blog post and the data I’ve shared can be useful to other teams.
Feel free to reach out on Twitter!